- 发帖可能变空内容,邪门暂不知所以然
- 『稷下学宫』新认证方式,24年网站打算和努力目标
主题:【半原创】Flickr 网站架构研究(1) -- 西电鲁丁
家园 【原创】Flickr 网站架构研究(5) "Flickr File System"探秘(上)Flickr在美国东西海岸各建了4个数据中心用于提供静态内容(主要是照片)的后台访问服务,组成了4个相互镜像和冗余的“Photo Farm Pair",各自服务于不同地域的客户。同Flickr"Master-Maste Pair"数据库一样,每个数据中心的设计容量是能够处理整个"Pair"100%的访问,这样在"Pair"中的一个数据中心因为停电,地震等灾难或必要维护而停止服务时,另一个数据中心仍然能够支持全部的访问而不降低性能。
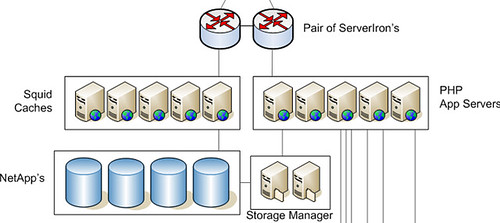
每个"Photo Farm"的架构示意图如下:
 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改这个就是所谓的"Flickr File System",主要由三部分组成:1)Perbal(未在图中标出)和PHP APP Servers提供文件访问的权限控制,获取文件的内部URL并转向Squid/Apache服务器;2)Layer 7 Load Balancer和多台Squid/Apache Servers(Apache未在图中标出)提供文件“读”访问服务;3)几台Storage Managers用于文件“写”访问服务,PHP APP Server和Storage Manager之间采用了Flickr自己开发的“文件传输轻量协议“。NetApp用于文件存储,Squid/Apache Server和Storage Manager Server和NetApp之间采用NFS连接。
我们先来看访问控制这一部分。
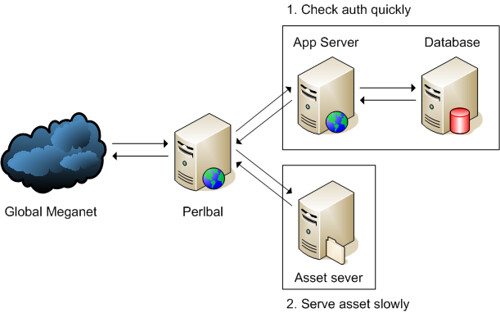
Flickr的访问权限控制是通过Perlbal(Perlbal是一个Perl 编写的单线程的事件驱动服务器,可充当 reverse proxy,Web 服务器 和 HTTP Balancer,与大名鼎鼎的memcache同出于www.danga.com)的"reproxy"功能来实现的,如下图:
 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改例如,当Perlbal收到以下URL访问请求时,”http://www.flickr.com/photos/41174610@N05/3999568691/“,首先将访问请求转向后台的PHP App Server 进行权限检查,如果当前浏览器用户具有访问权限,则向Perlbal返回HTTP Response 200,并设置"X-REPROXY-URL" Header为实际的静态URL地址,既”http://farm3.static.flickr.com/2434/3999568691_d836afbb57.jpg“,Perlbal收到X-REPROXY-URL后,将请求转向Asset Server既Squid/Apache Server进行处理,整个过程对用户透明。
以上例子中我们看到Flickr采用了两种不同方式的URL格式,第一种方式(例如”http://www.flickr.com/photos/41174610@N05/3999568691/“)我们姑且称之为“动态URL",当最终用户采用这种方式访问时,后台系统将进行权限检查;而如果用户采用第二种方式(例如”http://farm3.static.flickr.com/2434/3999568691_d836afbb57.jpg“),我们姑且称之为“静态URL",系统将略过权限检查,直接指向Squid/Apache服务器。这就是Flickr所谓“Permission URLs”的概念,即将授权信息作为URL的一部分,从而省略授权过程而提高网站的访问性能和吞吐量。
个人认为,Flickr是鼓励采用其Flickr API开发第三方接口的合作伙伴采用这种“静态URL"方式的。Flickr的API文档中提供了这种静态URL的信息格式
”http://farm{farm-id}.static.flickr.com/{server-id}/{id}_{secret}.jpg“
or
”http://farm{farm-id}.static.flickr.com/{server-id}/{id}_{secret}_[mstb].jpg“
or
”http://farm{farm-id}.static.flickr.com/{server-id}/{id}_{o-secret}_o.(jpg|gif|png)“
Size Suffixes
The letter suffixes are as follows:
s small square 75x75
t thumbnail, 100 on longest side
m small, 240 on longest side
- medium, 500 on longest side
b large, 1024 on longest side (only exists for very large original images)
o original image, either a jpg, gif or png, depending on source format
“静态URL"也可以通过“动态URL”来获得,而且是“终生授权”,即使将来作者修改了照片的权限,采用静态URL依然可以继续访问,除非作者删除照片,或者对照片进行修改,一旦照片经过修改,则系统自动生成一个新的“静态URL",原有的授权则因URL不存在而自动失效。
对于Flickr这类以"照片共享"为主要目的的社交类网站,安全并不是其首要的考虑因素,因而采用这种“折衷”方式的权限控制方式是可以接受的。(听说Amazon S3也是采用了这种方式,不禁为那些S3商业用户的数据安全悄悄捏了把汗
 )"Flickr File System"探秘(中)
)"Flickr File System"探秘(中)对于Flickr这样每秒需要响应和处理4万个以上的照片文件读取请求的大型网站系统,Web Cache和reverse proxy系统的重要性,无论怎么强调都不过分。常见的Web Cache系统有,Squid,Varnish,Apache mod_cache等。
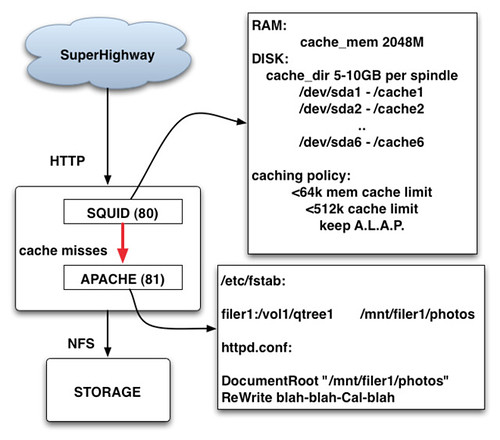
Flickr采用Squid作为缓存代理服务器,这里有一张2005年Flickr展示的系统配置原理示意图:
 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改简单解释一下,Squid采用2GB 内存作为一级缓存(注这个值仅仅是Squid用于缓存的内存大小,Squid实际所用的内存要大于这个值);服务器内置的6块15K RPM 高速硬盘作为二级缓存;小于64KB的文件缓存于内存,大于64KB而小于512KB的缓存于高速硬盘;当缓存空间不够时采用LRU(Least recently used)算法将”最近最少使用的文件“清除。
对于不在Squid缓存的文件,Squid则将请求转向Apache Web Server,Apache 根据ReWrite规则将URL转化成实际的NFS路径并取得相应的文件返回(图中只列出了一个Filer卷,实际上每个Squid服务器通过NFS mount了多个NetApp Filer的所有的卷)。值得一提的是,Apache在处理大于10MB以上的文件时,性能会有显著的下降,这也是为什么YouTube采用lighttpd的原因,所幸的是,一般照片的尺寸远远小于10MB,因而Flickr并不需要考虑额外维护另外一个Web Server,Apache已经足够满足需要。
Web缓存代理服务器常见的两个问题是:
1)如何避免”多次缓存“,即我们希望同一份文件只缓存一次,而不是在多个Squid中保留多份COPY,以最大限度的利用缓存空间。解决这个问题的办法是在Squid服务器集群之前放置Layer 7的Load Balancer。相对于传统的基于IP地址加PORT端口的Layer 4的Load Balancer,Layer 7的Load Balancer可以根据规则,对应用层的信息,如HTTP的Header,URL,Cookie Name等进行哈希或CRC计算,从而确保同一URL的请求总是指向后台集群中的同一台Squid服务器。
根据需要和负载,网站可以选择基于硬件的Layer 7 Load Balancer,如Flickr;也可以选择开源的软件方案,如具有Layer 7负载均衡功能的HAProxy,Perlbal,或者是利用Apache的mod_rewrite功能通过script来简易实现,示例代码如下:
RewriteEngine on
RewriteMap balance prg:/var/balance.pl
RewriteLock /var/balance.lock
RewriteRule ^/(.*)$ ${balance:$1} [P,L]
每一个到达的URL请求将被转向到/var/balance.pl脚本,由balance.pl脚本决定最终由哪台Cache服务器提供服务。
#!/usr/bin/perl -w
use strict;
use String::CRC;
$|++;
my @servers = qw(cache1 cache2 cache3);
while (<STDIN>) {
my $crc = String::CRC::crc($_, 16);
my $server = $servers[$crc % scalar @servers];
print "http://$server/$_";
}
(以上脚本省略了fail-over和后台服务器状态检查部分)
2)如何处理缓存”过期”问题,即当后台文件(如照片)修改后,如何保证用户能够访问到最新的版本而不是过期的版本。简单的更新Squid缓存并不总能解决问题,过期的文件依然有可能缓存在客户端的浏览器Cache,或是互联网上CDN,Proxy Server等处,而且还增加了后台应用的处理复杂程度和系统负荷。
Flickr的方案是引入了“虚拟版本”的概念(对于Flickr这样的应用,没有必要采用真正的版本管理和维护多个版本),让我们来回顾一下Flickr "静态URL"的格式:“http://farm{farm-id}.static.flickr.com/{server-id}/{id}_{secret}.jpg”,
每当用户修改照片时,数据库将重新生成一个新的的版本号码,即{secret}号码,从而产生一个新的静态URL并返回给客户,原有的缓存中的老文件则随着时间而“自然死亡”。(为了节省I/O,真正的物理文件名是没有这个{secret}号码的,在Apache的ReWrite处理中将这一部分去掉了。)这种方案,应该说至少可以保证通过“动态URL”访问的客户总是取得最新的文件版本,通过Flickr API访问的用户,则总是可以通过相应的应用逻辑判断来获取最新的“静态URL"。至于那些的Bookmark在浏览器端的旧的“静态URL",看起来也只能听之任之了,好象也没有更好的办法。
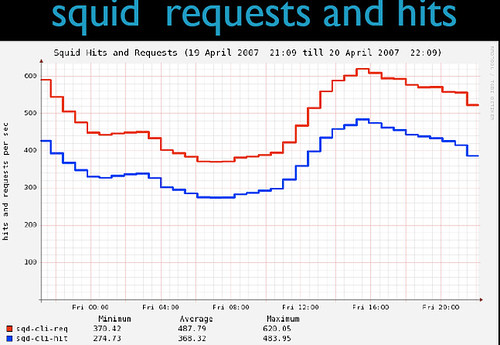
Flickr的缓存系统是相当高效的,这里有一些2007年的数据:
 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改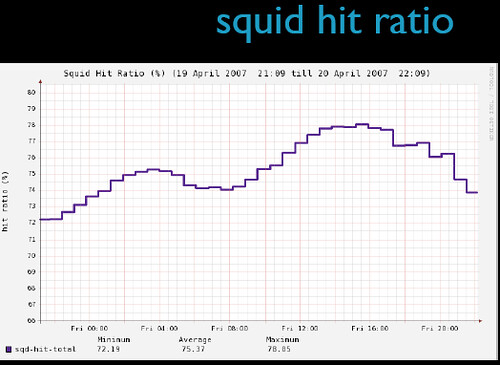 外链图片需谨慎,可能会被源头改总体来看Squid的命中率在75%-80%之间,命中时的响应时间为15-50ms,应该是相当不错了。Flickr的运营团队得出的结论是在当前服务器配置下,每一台Squid服务器可以支持每秒900-1000个请求,同时响应时间控制在100ms以内。换句话说就是,随着业务的发展,当每秒新增加900个请求时,只要添加一台新的Squid服务器就可以了。
外链图片需谨慎,可能会被源头改总体来看Squid的命中率在75%-80%之间,命中时的响应时间为15-50ms,应该是相当不错了。Flickr的运营团队得出的结论是在当前服务器配置下,每一台Squid服务器可以支持每秒900-1000个请求,同时响应时间控制在100ms以内。换句话说就是,随着业务的发展,当每秒新增加900个请求时,只要添加一台新的Squid服务器就可以了。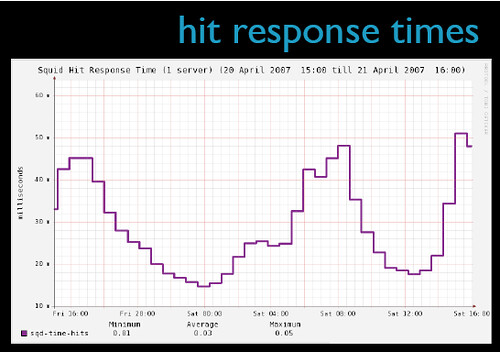 外链图片需谨慎,可能会被源头改通宝推:铁手,
外链图片需谨慎,可能会被源头改通宝推:铁手,家园 能让门外汉看懂的技术文章,了不起呀 家园 谢谢鼓励。
家园 看一遍不够 刚才看了一遍,没有发现什么疑问。
通常情况,如果没有疑问,多半说明没看明白,还得反复看。
估计是办公室太热了,头脑昏昏。看这些文章,得找个凉风习习的去处。。
回头再读,再读,直到读出问题来。
家园 先送花再学习 每个数据中心平时的负载只是其可最大负载的50%,这样在"Pair"中的一个数据中心因为停电,地震等灾难或必要维护而停止服务时,另一个数据中心仍然能够处理全部的访问。这部分看起来有一些浪费?现在是否可以使用云来替代?还是云在某些方面满足不了flickr的要求?
如何避免”多次缓存“,即我们希望同一份文件只缓存一次,而不是在多个Squid中保留多份COPY,以最大限度的利用缓存空间。解决这个问题的办法是在 Squid服务器集群之前放置Layer 7的Load Balancer。相对于传统的基于IP地址加PORT端口的Layer 4的Load Balancer,Layer 7的Load Balancer可以根据规则,对应用层的信息,如HTTP的Header,URL,Cookie Name等进行哈希或CRC计算,从而确保同一URL的请求总是指向后台集群中的同一台Squid服务器。原来flickr是用这样的策略做负载均衡的,有意思,这样确实能保障squid缓存的内容不同,后面的图表也能看到缓存命中率不错,但是这样做从另一个角度看人为增加了群集节点的差异性,在failover和管理方面会比较麻烦,例如,如果负责A内容的squid节点当掉,在添加进新的节点或者转移请求到其他节点之前,A内容缓存命中率为0,加入新节点或者转移到其他节点之后,缓存命中率也有一个上升的过程,也就是说,有降低整体性能的可能。或者说,在flickr的负载平衡策略里面还有什么花样?让squid节点缓存内容适度形成交集?如果是,那么交集的决定策略又是什么?
做个大站,费神的事情真不少。。。
- 复 先送花再学习
家园 【讨论】好问题,送花并试着回答一下 1. 50%的说法确实不太准确,已改为“每个数据中心的设计容量是能够处理整个"Pair"100%的访问”。事实上由于东西海岸的数据中心服务于不同地域的客户,时差不同,不会同时处于峰值,这样系统的冗余应该没有50%这么大,考虑到突发事件和“灾备”的作用,这部分冗余应该是可以接受的。
一个小故事是:2005年7月,Yahoo收购Flickr后刚刚把Flickr网站从温哥华移到德州的Yahoo数据中心,在修改DNS指向新的数据中心后才一小时,伦敦地铁发生爆炸案,当地人将不少照片上载到Flickr,随后是大量的互联网报道链接指向这些照片,Flickr的访问量激增,远超以前的峰值,如果不是新数据中心有足够的容量,Flickr恐怕就"挂"掉了。
云计算,看起来很美,实际还有很多细节没有解决,比如很多云服务提供商的SLA条款不够完善,对于租用者来说很难量化并监督以保证对最终用户的服务质量;由于对于租用者来说是个”黑盒子“,所以很难把握系统的实际性能及运行情况,给系统监控和容量规划带来困难;应用架构可能需要调整以适应云计算等等。另外,从费用来讲,云计算并不一定便宜,实际上不同企业情况不同,不能一概而论。
2。关于Squid的问题,其实可以细分为以下几个问题
1)Squid是否支持复制功能(replication)?
这个我不是Squid专家
,好象没看到,看到的功能都是如何防止duplicate.道理上讲在Layer 7的Load Balancer的规则上做点手脚,比如哈希后”模2" 等,让Load Balancer将特定的URL指向两台Squid服务器中的任意一台,好象是可以实现的。2)一台Squid失效,对Farm或者整个网站有多大的影响?根据2007年的数据,Flickr每秒处理4万个文件访问请求,而图中一台Squid的每秒峰值是620,平均值不到500个,粗略计算得知,Flickr应该有大约80台Squid服务器,每个数据中心大约10台左右,那么损失一台总体上对于一个数据中心的影响仅10%,对整个网站则几乎可以忽略不计了。
3)一台Squid需要多少时间Warm up? 不知道。
 哪位河友能提供一下数据?
哪位河友能提供一下数据?家园 Squid是用BerkeleyDB 实际上没有什么太大花头。我用berkeleydb做过一个类似的server,每秒每台机器的平均请求在600左右。每次请求数据传输在1k到10k之间--当然比flickr小多了。但是监控性能下来,目前只达到系统负载的25%左右。一台机器的数据总量在200到300GB,具体多少我忘记了。平均相应时间在10ms以下。当然,这是我server内部的数据,对用户的网络接口在我server的前面。仅仅反应的是berkeleydb所能处理的吞吐量而已。
话说回来,squid所作的cache基本上都依赖于berkeleydb来做,他做的事情是根据http协议做的一些优化(理解可能有误)。如果自己需要做某些简单的cache,不如用berkeleydb更来得合适。实际上,我觉得bdb还不太合适。B+tree做cache有些overkill,如果没有什么频繁的数据更新,用lucene效率更高。要不是现在我们的产品负载还可以,我是想把数据移入lucene的。
家园 谢谢yueyu兄参与讨论,花谢 没看过berkeleydb的资料,不好评论,看起来主要的结构是key/data pair,应该没有太多的overhead.
Flickr自己说Squid在overload情况下会占用很多cpu和network资源,达到100%,他们也考察过varnish,据说在一些情况下效率更高,不过好象还不太稳定。另外Facebook用的是memcache做文件缓存,我在下一篇会提到。
关于lucene,这不是搜索引擎吗?怎么反而效率比专门的缓存服务器还高?
家园 这个,要看用途啊 flickr做的cache实际上是不适合用lucene的,因为更新太多了,所以需要用update更高效的B+ tree。
而我们的应用,很少更新,仅仅是纯cache。lucene虽说是搜索引擎toolkit,但是数据结构是用inverted index,在IO方面,做了很大的优化。在纯query操作,速度明显高于B+tree。而大数据量的cache,IO是必须优化的。B+tree在数据量到一定程度,index比数据本身还大的多,而且不容易压缩。而inverted index长处在于数据结构简单,可作的优化非常多,而lucene也做了这么多优化的。
具体的,我没空找相关文章了。
整体来讲,squid是一个通用的cache system,未必适合特定的应用,或者说特定的应用可能有更好的做cache的办法的。