- 发帖可能变空内容,邪门暂不知所以然
- 『稷下学宫』新认证方式,24年网站打算和努力目标
主题:【原创】新冠病毒起源小议 -- 澹泊敬诚
下面都是从“中国科学院西双版纳热带植物园官方网站”摘的。
想看的自己去看
[URL=http://www.xtbg.ac.cn/xwzx/kydt/202002/t20200220_5502619.html ]http://www.xtbg.ac.cn/xwzx/kydt/202002/t20200220_5502619.html [/URL]
1 演化路线
——>蝙蝠冠状病毒RaTG13
——>中间载体(mv1,可能是祖先单倍型,也可能是来自中间宿主或“零号病人”)
——>H38、H13(美国华盛顿h38、广东深圳h13登场,看附件)
——>单倍型H3(澳大利亚、中国台湾台北、比利时鲁汶出场)
——>衍生出单倍型H1(武汉华南海鲜这时候登场)
——>衍生单倍型H2,H8-H12
——>其他单倍型。
2 与华南海鲜市场有关联的患者样品单倍型都是H1及其衍生单倍型H2,H8-H12,而一份武汉样品单倍型H3与华南海鲜市场无关。
3 H13和H38的病毒样品溯源发现,分别来自深圳的病患(广东首例)和美国华盛顿州的病患(美国首例)。现有武汉样本中没有检测到H13和H38单倍型。
4 研究人员将58种单倍型分成了五组(图1),采用标准是3个中心(古老超级传播者)单倍型(H1,H3和H13)和2个新的超级传播者单倍型(H56和mv2)。有较多样本的澳大利亚、法国、日本和美国,他们的患者感染源至少有两个,尤其是美国包括了五个来源。【这个尤其用得好】
文章写到这里,嘎然而止,想说的都说了,你想听的,人家一句都会不说。
我也不说,偏不说。
2
再补充一点,文章作者来自中国科学院西双版纳热带植物园,韶关大学霍英东生物与农业学院,华南农业大学,中国大脑研究所,北京102206。
这篇文章意思是,有两个中间宿主,三个零号病人。
真是不能讨论了。
- 待认可未通过。偏要看
土鳖辛苦了。
近两个月随着疫情的扩散和加剧,大家对于新冠的了解越来越多,各种解读、分析层出不穷,在这提供一点冠状病毒的基本信息,抛砖引玉,期待众河友的讨论和指正。
虽然近几个月关于新冠病毒的研究文章不断涌现,从开始阶段的测序、生物信息学分析,到近期的蛋白结构和生化细胞分析,但我们对于新冠的了解非常的初步,甚至可以说我们对于整个冠状病毒的了解都是很有限的。新冠COVID19和SARS在病毒行为上比较类似,这里介绍的多基于SARS的研究,以作为了解新冠感染传播机制的基础。
先说几点基本概念和原则,有助于我们的理解和分析
1.生物体的所有行为,包括摄食、求偶、繁殖/增殖等,都可以归因于为了将自身的遗传信息复制和传递下去(子曰:食、色,性也。)。遗传信息的基本单位一般认为是基因,即所谓的“我们是满载基因航行过生命的一艘小船”。
2.生物遗传信息以碱基序列的形式储存在DNA(脱氧核糖核酸)或RNA(核糖核酸)上,二者都是核苷酸组成的多聚链,核苷酸的碱基之间可以互补配对(G-C和A-T/U)
3.DNA和RNA都可以在酶的作用下通过互补配对,合成互补链。以DNA/RNA为模版合成DNA/RNA链一般称为复制(replication),以DNA模版合成RNA链多属于转录(transcription),以RNA模版合成DNA链称为逆转录(retrotranscription)
4.蛋白质只能以RNA为模版在核糖体上合成,不能反向指导DNA或RNA的合成,即遗传信息只能从DNA/RNA向蛋白质单向传递。在分子病毒学中,能够作为蛋白质合成模版的RNA链称为正链。对应的,与正链互补的RNA链为负链。
好,了解了以上4点,我们可以来了解冠状病毒的基本信息了。
就是说这个病毒的基因组只有一条RNA,这条RNA可以作为模版直接指导蛋白质合成。
我们常提起的埃博拉病毒是负单链RNA病毒,而流感病毒基因组由8条负链RNA组成,乙肝病毒是环状DNA,人体免疫缺陷病毒(HIV)含两条正链RNA,但需要先反转录成DNA,整合到宿主细胞基因组中再进行复制扩增。这几种病毒之间的差异非常大,大到可以互相说“你们都是虫子” 。
。
冠状病毒外被囊膜(envelop),是包裹在病毒粒外的双层脂膜,源自于病毒从细胞中裂解而出时的细胞膜。这层膜把病毒包成球形,加上附着在其表面的棘突蛋白(spike,S),构成了冠状病毒特有的日冕(corona)形态。
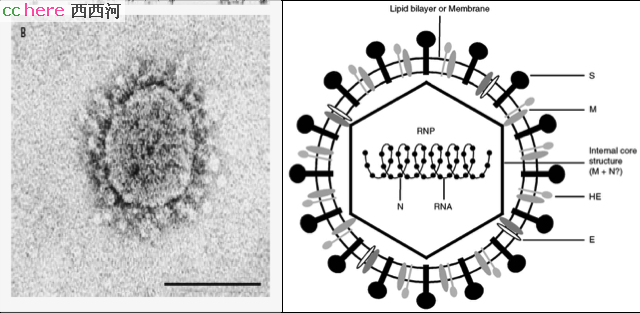
囊膜里面是螺旋形的核衣壳,内部是病毒的基因组:一条约30,000个碱基(30 nt)组成的单链RNA,是RNA病毒中最大的基因组。
当冠状病毒脱去囊膜和核衣壳,坦荡荡地出现在宿主细胞内的时候,迎来了毒生的终极问题,怎么把自己复制出来?
病毒嘛,能用宿主的就不用自己的,但遗传信息还是得弄自己的不是。想搞出和自己一模一样的正单链RNA,首先得有一个负链模版。冠状病毒无法像HIV一样进行逆转录,所以DNA模版就别想了。剩下的就只有用自己做模版先合成出互补的负链RNA,再用这个负链做模版合成出和自己一样的正链来。
模版的问题解决了,但环顾四周,靠RNA模版合成RNA的酶(RNA-dependent RNA polymerase, RdRP) 宿主细胞内真没有啊。冠状病毒一跺脚,我们带着酶上路!
在冠状病毒基因组的前2/3,编码了一个巨大的复制转录复合物(Replication-Transcription Complexes, TRC),由15个非结构蛋白(non-structural protein, Nsp)组成,负责合成负链和稍后的正链RNA。由于冠状病毒本身是正链RNA,可以借用宿主的翻译系统来合成蛋白质,首先合成的正是这个位于基因组前部的RNA合成酶复合物,用以完成后面的RNA合成。
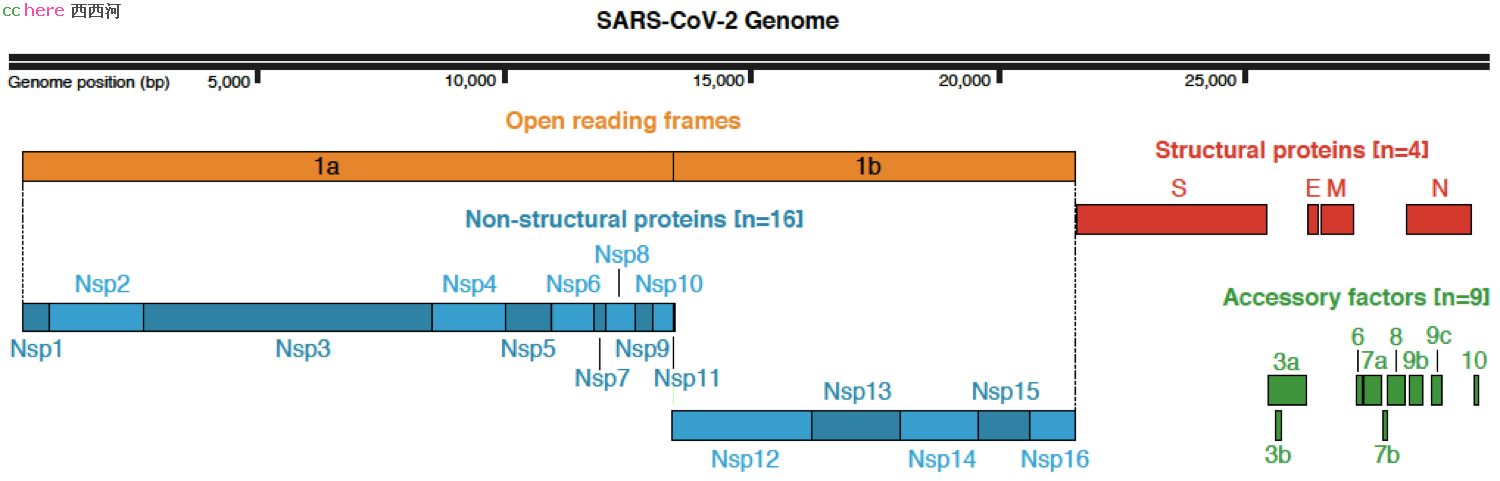
基因组的后1/3编码了一些列作用尚不明确的辅助蛋白(accessory protein)和四个结构蛋白(structural protein):核衣壳蛋白(nucleocapsid, N)组成核衣壳,包裹基因组RNA;囊膜蛋白(envelop, E)参与病毒的组装和释放;膜蛋白(membrane, M) 位于囊膜上,也与核衣壳蛋白结合;棘突蛋白(spike, S)位于病毒表面,用于识别和入侵宿主细胞。这一系列蛋白稍后也通过宿主的核糖体进行合成,位于囊膜上的E、M、S蛋白通过内质网-高尔基体途径转移到细胞膜上,等待N蛋白和正链RNA组装成为衣壳粒的来到,破宿主细胞而出,成为成熟的病毒,开始新一轮感染过程。
冠状病毒的显著特征之一就是基因组前大半的RNA合成酶(RdRP),检测冠状病毒核酸的方法之一就是看样品中有没有RdRP的基因被聚合酶链式反应(polymerase chain reaction, PCR)扩增出来。同样地,RdRP如此重要,又为病毒所特有,所以是理想的药物靶点,瑞德西韦(remdesivir)就是通过抑制RdRP的活性来控制冠状病毒感染。
土鳖来辛苦一会儿吧……
两个月过去,开头提到的Andersen的文章已经发在了《自然 医药》(Nature Medicine)上面,总结起来,他说了两个方面的原因:新冠既和我们能想到的改造方式不同,也没有人工制造的痕迹。
先说后者,我的观点有所不同:现在的分子生物学技术,是能够制造出“不着痕迹”的人工冠状病毒的。
制造冠状病毒的关键步骤就是造出其基因组,那条30 kb长的单正链RNA。在宿主细胞中有效表达的单正链RNA,就能够自我完成RNA复制、蛋白质合成、病毒组装和释放的所有过程。
造RNA链的难度比DNA链的难度大很多,因为RNA本身不稳定,而且无法有效进行分子克隆等操作,但我们如果有了长DNA链作为模版,扔进宿主细胞,就可以转录成长RNA,进而制造出病毒。所以问题就转化成了如何获得一个长的双链DNA链模版,这就相对简单多了。选择双链DNA是因为单链DNA不稳定,而且不好做克隆。
直接化学合成长链DNA是不靠谱的。现在的DNA固相合成的上限是几百个核苷酸长,随着长度的增加,产率快速下降,错误率急升,到不了1000 nt就剩不下什么了。
但我们能够做一系列的短DNA片段(60-500 nt),然后想办法短片段拼成长片段。传统的方法是先通过聚合酶链式反应(PCR)扩增一系列冠状病毒基因组DNA片段,并且在这些片段添加特定的限制性内切酶识别位点,通过限制性内切酶酶切,让片段的末端成为两条链一长一短的粘性末端,不同片段的粘性末端互补配对,再通过连接酶把这些配对起来的片段连起来形成长链。比如2015年那篇引起争议的改造SARS病毒文章,用的就是这个思路,具体方法发表在2003年的美国科学院院刊。这个方法的效率比较低,而且会留下使用的限制性内切酶识别位点,成为人工操作的痕迹。当然,精细选择合适的内切酶可以让这些位点在克隆操作中被抹去,但这个办法比较看运气,如果基因组中正好有这个识别位点,就不能用该内切酶了。
2009年Gibson克隆技术把分子克隆变得“简单粗放”,不再依赖于限制性内切酶的切割,而是通过核酸外切酶造成更长的粘性末端,不同片段粘性末端互补配对,再通过DNA聚合酶补齐+DNA连接酶连接,来形成没有克隆痕迹的长链DNA。这个技术对于合成长链,尤其是基因组级别的DNA非常有帮助,成名作就是2010年由Craig Venter领导的合成生命:Gibson克隆结合酵母同源重组相,从核苷酸开始合成了1百万个碱基对的环状基因组,并成功在细菌内实现了生理功能和自我复制。
今年2月,瑞士的一个组也用类似的方法快速合成了MERS和COVID19的基因组。
所以合成冠状病毒的基因组并且抹去人工操作的痕迹从理论上是可行的,但是科研面对的难点不是怎么做,而是做什么,即怎么改造病毒。
改造基因和蛋白质的科研工作者一般是“既怂又懒”的,能够抄一段已知的功能明确的的片段就不做改动,能够改一个氨基酸残基就不改两个,能够修改就不做删除或插入,能够局部改动就不做几个不同来源片段的拼合,能够拼拼补补就不从头全新设计。究其原因是我们对蛋白质序列与结构功能的关系所知太少,改造中不得不采用保守的策略,尽量减少对天然蛋白结构改变来达到我们的改造目的,以避免出现我们无法预期的变化。无中生有地造出一个全新的蛋白序列,且满足独特的结构和功能对于现在的我们是非常难的。因此当草台班主James Lyons-Weiler 在电视上说新冠S蛋白找不到已知相近的核酸序列,所以是人造病毒的时候,他的生物学博士真的是白念了。
从1962年Anfinsen核酸酶折叠实验表明蛋白序列决定其三维结构开始,半个多世纪的时间我们研究了很多蛋白的序列、结构和功能。基于这些积累的信息,现在我们已经能够用算法来“猜”一下新蛋白的结构和功能,但也只限于猜的水平,准与不准还是得通过结构生化细胞的方法去实地验证。近10年来,以David Baker为代表的一批科学家开始尝试蛋白从头(de novo)设计,对于小蛋白有了较好的结果。需要强调的是,我们现在掌握的算法还是基于对已有蛋白信息的学习和分析,自然界中存在着太多的蛋白结构和功能是我们不知道的,每一个新蛋白结构的出现,都拓展并且颠覆了一些已有认识,让我们对蛋白的理解更加深入和多样。这也是Andersen所说的,新冠Spike与和我们现有预测方式得到的结果完全不同。打个比方,我们围棋开局刚下了个星位,对面的AlphaGo不管什么入界宜缓,直接点三三进来,这不是我们已有的棋理能预测的。