- 发帖可能变空内容,邪门暂不知所以然
- 『稷下学宫』新认证方式,24年网站打算和努力目标
主题:alphaGo 系统以及人工智能的未来 -- pattern
2016年1月28日,Google Deepmind在Nature上发文宣布其人工智能围棋系统AlphaGo历史性的战胜人类的职业围棋选手。预定2016年3月份AlphaGo对阵李世石的比赛更将引起全人类的目光。alphaGo 系统是基于人工智能中的 深度学习算法的,我恰好也做了一些这方面的工作,觉得可以介绍一些这方面的情况。
图像识别系统的深度学习算法
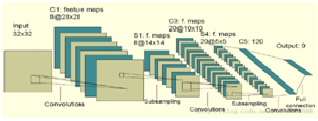
去年(2015年) 2月15日,有一条很重要但是公众不怎么注意的消息,微软公布了一篇关于图像识别的研究论文,在一项图像识别的基准测试中,电脑系统识别能力已经超越了人类。人类在归类数据库ImageNet中的图像时错误率为5.1%,而微软研究小组的这个深度学习系统可以达到4.94%的错误率。在去年年底的比赛中,微软研究员何恺明、张祥雨、任少卿和孙剑组成的团队又获得第一,把错误率降到了3.57%。这个在图像识别系统中取得突破的算法就是深度学习算法。深度学习算法是普通神经网络的更多层的深化。
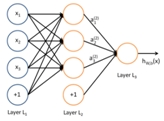
神经网络由单个的神经元组成:
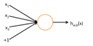
这个“神经元”是一个以 x1,x2,x3及截距 1为输入值的运算单元,其输出为 h,输入输出为非线性关系。微软去年底的突破是因为发展了一种深达152层的网络。
alphaGo 系统如何学习下棋
alphaGo 系统充分利用了图像识别的成果。它把19*19的棋盘当做19*19像素的图像来处理。 Google团队设计了一个13层的类似图像识别的深度学习网络。利用KGS Go 服务器上的高手对弈样本来学习。这样通过学习后生成了一个策略网络,这个策略网络无需搜索就达到了57%的准确率。形成策略网络后,系统使用这个网络自我下棋,并使用胜利一方的棋局强化学习。通过这样的自我强化学习,系统的准确率达到了80%。无需任何额外的搜索,仅仅使用强化学习过的策略网络和另外一个使用蒙特卡洛的软件PACHI比赛时,胜率为85%。
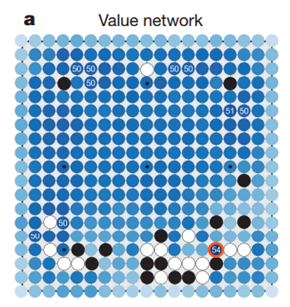
使用和策略网络差不多的方法,google还训练了一个评价网络来评估当前的整体局势。这个评价网络用来给当前的棋局打分。同样通过强化学习后,这个打分的误差小于0.24.
最后alphaGo 系统使用策略和评价网络来搜索最好的棋子落点。使用这两个网络可以极大减少搜索的范围,但是使用这两个网络使得单步计算的时间比蒙特卡洛方法要长,综合下来alphaGo系统还是需要强大的计算能力。

alphaGo 和李世石谁会赢?
李世石观看过alphaGo和樊晖的棋局后,认为alphaGo和自己有让两子的差距。不过和李世石比赛的 alphaGo应该有了很大的进步。基于网络的同质性,图像识别方面的进步肯定会反应到围棋算法上来,我想得到的第一个进步就是原来的13层网络还可以加深,比如加深到26层。这样网络的初始胜率估计会提高几个百分点。第二个进步是针对李世石的棋谱进行强化训练,这种方法对应于在图像识别时就是更多训练难以识别的图像。这样改进后,再考虑到人有时候会犯错,我认为alphaGo有可能赢上一盘。
人工智能和人类智能的区别
那么人工智能究竟发展到什么程度了?是不是战胜围棋高手就是达到了成人的水平?其实深度神经网络用的还是大数据的方法。比如要训练一个认识猫的网络,那么你需要成千上万张各种各样猫的图片来训练,告诉网络这样的图是猫。可是一个两岁的小孩,只要见过一只猫,就能识别出他以前根本没看见过的动物是一只猫。所以虽然深度学习的基础是模仿了人类脑神经的工作方式,但是实际上两者的工作方式应该是截然不同的,人工智能和人类的智能还无法直接比较。
人工智能的未来
深度学习的概念由Hinton等人于2006年提出。近几年来在图像和视频理解,语音识别,自然语言处理等方面都取得了很好的进展。令我印象最深的是自动驾驶方面的应用。google,百度等互联网巨头都投入巨大,并且已经在实验中取得了很好的效果,已经在逐步商业化的过程中,未来5年内应该会有可行的自动驾驶汽车上市。蒸汽机,汽油机,电动机把人类从繁重的体力工作中解脱出来,而人工智能将会把人类从低端的脑力劳动中解放出来,使人类的生活上一大台阶,乐观一点的话,五年后工业机器人大批应用,十年后各种家庭智能机器人会象电冰箱,洗衣机,空调等电器一样成为家庭必配。
比如开车总会发生磕磕碰碰,下棋高手总会出臭棋。
人工智能可以减少犯错,在下棋上无所谓,在驾车上就是功德无量了。
如果在alphaGo 和李世石比赛的时候临时把棋盘调整为29*29的大棋盘alphaGo会受多大影响?
如果给alphaGo 和李世石一年时间来适应29*29的打棋盘,情况会有什么变化么?
扩大棋盘大小对机器来说不过是多几个参数的问题,理论上来说应该是机器完胜。但对人来说,从小训练以及选拔出来的规则、直觉、技巧全部作废。
但问题是找不到足够的训练数据供机器去学习。
所以最终的结论应该是一年后李世石胜,但是多下几盘之后,机器迅速赶上并超过。
机器学习可以使机器达到比人类高一点的水平,不会比人类高很多,因为初始的训练数据是人类提供的。
没有办法下,因为alphoGo 的所有学习都是针对19*19的,它的所有计算参数也是19*19的。
同样的道理,alphaGo 也没法和李世石打棋盘,因为alphaGo 的所有的原始智能来源于以前高手下棋的棋局(职业六段以上)。你给它规则,而不给它样本,它实际上并无法执行。
但是,里面有一个比较恐怖的细节是,alphaGo 实际上并不明确知道“两眼是活棋”这个规则,但是通过学习,它的网络里已经“学到”了这个规则。
大致上同意你的看法,但是alphaGo 可能有点特殊:因为它有个自我下棋,然后学习的方法。这个自我学习在其他人工智能上还没看到过,可能也很难实现。有了这个过程,我觉得它还是有可能超过人类的。
围棋样本量大,深度学习overfitting不会是大问题。其他样本量有限的体系,能简介下如何请教防止 overfitting吗? 谢谢!
围棋的规则很少。
19*19的棋盘,黑白二色棋子,轮流下棋;
死活规则文字描述起来非常拗口,不过放在棋盘上是一目了然的。
最后加上双方可能都出现无气状态的特殊情况的规定,围棋的基本规则就OK了。
“两眼活棋”其实不是基础围棋规则,而是从围棋死活规则中自然得出的推论,是对围棋死活情况的简明描述。
人类在游戏中制定规则、改变规则是很常见的,比如把用象棋比大小,用围棋下五子棋,还有扑克,那玩法就不知道多少了。
如果说只给电脑规则不给样本他就不知道怎么下棋的话那就很难说他有学习能力,只能说他仍然只是个工具。
死活规则:一个棋子在棋盘上,与它直线紧邻的空点是这个棋子的“气”。
直线紧邻的点上如果有同色棋子存在,这些棋子就相互连接成一个不可分割的整体。
直线紧邻的点上如果有异色棋子存在,此处的气便不存在。棋子如失去所有的气,就不能在棋盘上存在。
同样的道理,alphaGo 也没法和李世石打棋盘,因为alphaGo 的所有的原始智能来源于以前高手下棋的棋局(职业六段以上)。你给它规则,而不给它样本,它实际上并无法执行
当然要定义“一次”。
另外,人“一次”——一张图像得到的信息可能比计算机多。
不过也可能人的建模方式与计算机不同。
否则还是要想办法增加样本,比如做样本增强。
我的意思是婴儿不需要抓几百只猫来学习。
看看谁的设备既安全又快速。
对人来说,这种调整会有影响,但不可能就不会下棋了。
就像把篮球场地扩大到足球场大小,那排兵布阵肯定不一样,但是不可能就不会打篮球了。
对围棋来说,19*19调整为29*29大概会让职业9段变成职业3段,但是怎么也不会变成业余3段的。