- 程序有所改变。发帖如还有问题请报告
- 【征集】西西河的经济学,及清流措施,需要主动参与者,『稷下学宫』新认证方式,24年网站打算和努力目标
主题:关于我国基尼系数的真相和争论 -- hwd99
关于我国基尼系数的真相和争论
1. 统计局公布数据引质疑
最近国家统计局局长马建堂在1月18日发布会上,首次公布了最近10年来中国的基尼系数。2012年中国的基尼系数为0.474。国家统计局曾于2000年公布中国基尼系数为0.412,之后未见官方数据发布。
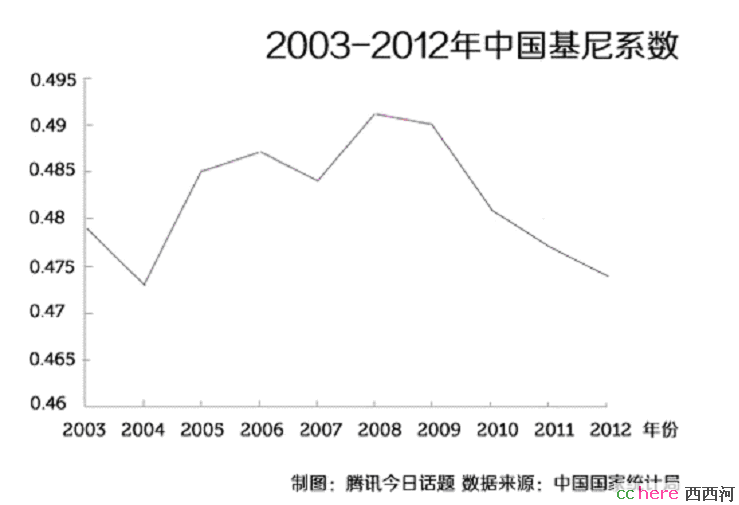
此前,西南财经大学公布的一份中国家庭金融调查结果显示,2010年中国家庭的基尼系数高达0.61;香港独立经济研究公司的一份报告则表明,近几年的中 国大陆地区的基尼系数都超过了0.55;而在由北京师范大学管理学院和政府管理研究院共同完成的《2012中国省级地方政府效率研究报告》中搜集的数据发现,各研究机构测试出的基尼系数结果都不尽相同,低的在0.43左右,高的在2011年也达到0.5,他们是国内最早开展我国基尼系数计算工作,曾发布2007年基尼系数为0.48。西南财大报告出来以后,他们提出了严厉质疑。
国家统计局局长马建堂解释说,官方民间数据不统一的主要原因是民间测算不够严谨。他还举例,世界银行测算的2008年中国基尼系数是0.474,而统计局公布的中国2008年基尼系数为0.491,暗示统计局数据高于世界银行,表明官方数据的准确性。
这一说法遭到各方质疑。中国社会科学院工业经济研究所研究员曹建海在接受采访时表示,国家统计局的这个数据“非常可疑”,因为中国的基尼系数近10年来持续增大,早已经超过了警戒线,并没有看到收敛的迹象。曹建海估计现在中国高收入家庭和低收入家庭之间的收入差距,不是国统局发布的4倍,而可能达60倍。一个不断降低的基尼系数趋势“意在掩盖近10年来政府政绩的不足”。
2012年9月18日,经济学家、燕京华侨大学校长华生在莫干山论坛上称,北京一个研究院说中国基尼系数现在是到了0.437,那是胡说八道,中国现在至少是0.5以上。
财经评论专栏作家叶檀则认为,根据有限的材料来看,国家统计局最大的可能性是低估了高收入人群的灰色收入,这将直接降低基尼系数。而西南财大有可能低估了低收入人群的收入。
著名经济学家李稻葵[微博]21日表示,统计局的基尼系数比实际的低,其主要原因是由于统计入户调查的样本偏于中低收入家庭,高收入太少。但国家统计局公布的基尼系数反映趋势完全可信,是经济大格局变化所致。
2012网易经济学家年会上,贺铿认为,我们的基尼系数仅比巴西等少数几个国家稍小,高于印度等国,我国收入差距是10.7倍,美国是8.7倍,印度为4.9倍。坊间早就猜测我们的基尼系数超过0.5了。
2002年北大教授厉以宁先生提出分组平均基尼系数计算新法,分别计算城市和农村基尼系数,然后再加权平均,算出一个总基尼系数,得到中国基尼系数仅0.32-0.35,称中国没有贫富分化。遭到网友们嘲笑,网友们创作了很多小段子,编排厉理论的荒谬,诸如证明武大郎和姚明一般高等等。
一句话,整个社会的普遍认识,是中国社会贫富分化严重,基尼系数非常高。反对这个看法的,要么遭到社会的耻笑,要么默默无闻。
2、基尼系数计算原理
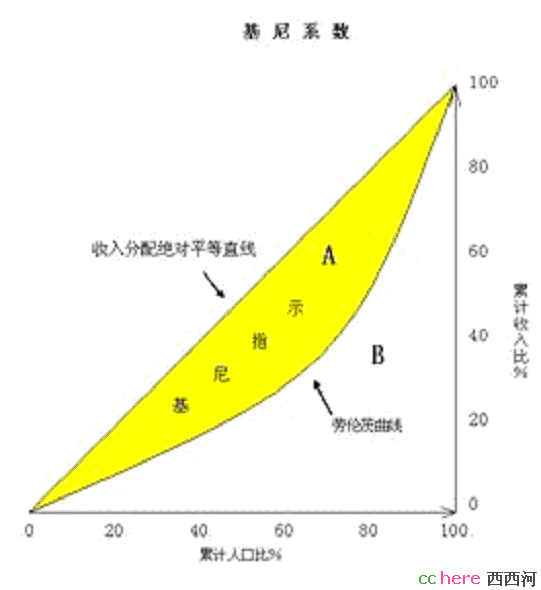
基尼系数是从洛伦茨曲线产生的。洛伦茨曲线的横坐标是人口(或家庭)百分比,纵坐标是收入百分比,基尼系数就是绝对平均分配的洛伦兹线与实际曲线所包围面积(图中黄色部分)的2倍,可通过积分洛伦兹曲线得到基尼系数。学过微积分或数值分析的同学都可以解决它。它适用于衡量一切社会的贫富差距,而不只是市场经济国家。从理论上说,绝对平均的社会基尼系数为0,全部收入集中于1%甚至1个人的社 会,基尼系数为1。这两种情况都不可能存在。国际上一般通用的分类是,低于0.2表示收入绝对平均;0.2——0.3表示比较平均;0.3——0.4表示相对合理;超过0.4表示收入差距过大,一般认为,0.4是国际警戒线,也有称之为黄色警戒线,将0.5称为红色警戒线。改革前中国的基尼系数约为0.2,属于绝对平均之列,但实际上,农民、 工人、干部、知识分子的收入都有差别,只是差别不大而已。
通常根据家庭和个人收入分布的统计数据,就可以容易地得到洛伦兹曲线。只要得到了洛伦兹曲线,计算基尼系数,在数学上就是比较容易的。问题是,统计资料经常不完备,难以得到洛伦兹曲线。我国在收入方面的统计资料就是这种情况。2012年3月7日政协会议,李毅中 、厉以宁等委员发问,为什么不公布基尼系数。国家统计局局长马建堂7日回应说,目前中国居民收入方面的调查是城乡分开的,基尼系数也是城乡分开的,发布全国统一的基尼系数有待于城乡住户调查一体化。
这一点李稻葵说得不错。
均平指数号称2008年后下降,等同于说2008年后共富效果凸显,换句话说就是不需要再实施共富的各种政策措施了。
可是,台上的人还在强调要共富,搞中国梦呢,这是打谁的脸???呵呵。
嗯,自从一个经济学博士掌管内政后,好像各种统计数字都开始飘忽起来,比如物价指数,比如这个均平指数。
然而,他一次又一次的以实际行动在狠狠地抽自己的耳光。执政十年,最大的败笔,就是让全国人民彻底失去了对政府的信任。
这次公布的基尼系数,不过是又消费了一次自己剩余不多的“信誉”。
ps:统计局真是有重新洗牌的必要了,以邱晓华为代表的统计局长们,个个极品。拜托局长大人即使公布假数据,也要有一点儿敬业精神才行。
又ps:厉以宁的算法已经改得面目全非了,又何必挂羊头卖狗肉,不如直接命名“厉以宁系数”得了
如果统计数字覆盖不了的收入是主要的收入差距的原因,显然现有统计反映不了趋势。李稻葵显然错了。
期间虽有反复,但证明了10年执政还是进步,有成绩的。。。。
3、我国公布的居民收入统计数据
国家统计局公布的有关居民收入的统计数据可分成三种情况:
1)2002-现在,主要统计数据包括城镇和农村家庭分组情况,给出各家庭组中人均收入和平均人口,其中城镇家庭分组是将调查家庭按户人均可支配收入由低到高排队,按5%,5%,10%,20%,20%,20%,10%,10%的家庭户数比例分组。农村家庭是分成相等的5等份,给出每个分组的平均收入。这两组数据可以容易地转换为洛伦兹曲线上的数据点。 此外,还给出农村居民按人均纯收入分组占调查户的比重,或者说,这组数据可以很简单地转换到按农村计算人均纯收入计算的家庭累积分布。
2)1984-2001,城市数据同上,部分年份也同时提供了按人均可支配收入分组的分布数据,农村数据只有农村居民按人均纯收入分组占调查户的比重数据。
3)1981-1984,城市数据包括了按家庭人均收入分组的分布数据,家庭人口数量及人均收入三种数据,这组数据可以同样转换到洛伦兹曲线上的数据点,农村数据同上。
根据统计局发布的统计报告介绍,城镇住户调查是由国家统计局住户调查办公室组织实施,国家统计局各调查总队及抽中市、县调查队依据国家统计局统一制定的城镇住户调查方案收集资料,逐级审核,由国家超级汇总。
调查对象在2001年以前为全国非农业住户,2002年以后改为全国城市市区和县城关镇区住户。
住户调查城镇采用分层随机抽样的方法确定,首先,按照城镇规模将全国所有省(区、市)的城镇划分为三层:大中城市(地级和地级以上的城市)、县级市和县城(镇)。第二、按各层人口占全省(区、市)人口的比例来分配每层的样本量。第三、按城镇就业者年人均工资从高到低排队,依次计算各城镇人口累计数,然后根据样本量的大小随机起点等距抽取所需数量的调查城镇。
城镇住户调查的调查户的抽选工作分两步进行。第一步进行一次性的大样本调查;第二步从大样本调查中抽出一个小样本,作为经常性调查户,开展记账工作。
大样本调查每三年进行一次,其目的主要是为经常性调查提供抽样框和为经常性调查数据评估提供基础资料。在大样本调查中,各调查市、县采取分层、二(多)阶段、与大小成比例(PPS方法)的随机等距方法选取调查样本。即先按区分层,在层内按照PPS方法随机等距抽选调查社区/居委会,在抽中社区/居委会内随机等距抽选调查住宅。部分大城市根据需要可以采用三阶段抽样,即先抽选社区/居委会,再抽选调查小区,最后抽选调查住宅。对选出的大样本或一相样本开展调查,取得调查户家庭人口、就业人口、收入等辅助资料,然后,根据这些资料进行分组,从中按比例抽出一个小样本也称二相样本,作为经常性调查户,开展日记账工作。
截止2010年底,参加国家汇总的调查样本量为65000户。
农村居民生活资料来源,农村居民生活状况的数据来源于国家统计局住户调查办公室的农村住户抽样调查。主要内容包括农村居民家庭基本情况、住房情况、收入、生活消费支出、主要消费品消费量、耐用消费品拥有量等。
农村住户调查方法:农村住户调查是以各省(区、直辖市)为总体,直接抽选调查村,在抽中村中抽选调查户。综合运用多种抽样方法确定住户调查网点。农村住户调查网点分布在全国7100多个村,共抽取了68000多个样本农户。
农村住户调查在95%的概率把握程度下要求抽样误差不得超过±3%。为保证农村住户调查资料的准确性,国家统计局住户调查办公室为调查户设置了现金和实物两本帐,并聘请了近万名辅助调查员帮助做好记账工作,及时核实、汇总住户调查资料。
4、其他机构公布的收入分布数据
我国统计局发布的收入分布数据的主要问题,是分成城镇和农村两个分开的群体,无法简单地根据这两组数据合成整体的收入分布数据,从而得到全体居民或家庭的洛伦兹曲线。
此外,还存在公布数据点少,例如,农村居民收入分成五个组,实际落实到洛伦兹曲线上只有四个点,难以给出精确的洛伦兹曲线。此外,到2001年为止,公布的农村居民收入数据是农村居民按人均纯收入分组占调查户的比重数据,这个数据中收入是人均纯收入,而分布则是家庭分布,两者不匹配,由于统计局没有提供各组家庭人口数字,依据这个数据,既不能得到个人收入分布曲线,也不能得到家庭分布曲线。
根据这种情况,部分学者和机构独立进行收入情况调查。
4.1 北师大:中国家庭收入项目 (CHIP)调查
在上世纪80年代末,Keith Griffin和赵人伟联合带领由中国以及国外研究者组成的团队,首次组织了一系列全国范围内的家庭住户调查,该调查即是后来被人熟知的中国家庭收入项目 (CHIP)调查。该项目旨在收集家庭调查数据,以用于分析改革开放以后的中国诸如收入、不平等以及贫困趋势的可能有益的经验分析。在上世纪90年代中期 赵人伟和Carl Riskin牵头组织了第二轮的调查,而在本世纪初期由Bjrn Gustafsson、李实和Terry Sicular组织了第三轮的CHIP调查。在1988年、1995年、2002年、2007年住户调查的基础上,形成了被国际学术界称为“CHIPS” 的数据库,被称为迄今中国收入分配与劳动力市场研究领域中最具权威性的基础性数据资料。现在学者可申请2007年以前的CHIPS数据。该数据库有28000个住户样本。从样本质量上来说,采样时,这些调查户被要求对每天的收入和支出情况进行记账,因而收入和支出的信息比较可靠。在估计收入差距时,对不同类型样本户根据城乡人 口,地区人口比例分别进行加权,根据国际上使用的收入概念对收入进行调整,考虑到了各种估计误差可能带来的影响。
4.2 美国北卡罗来那大学和中国预防医学科学院:“中国营养和健康调查” ( ChinaNutrition and Health Survey ①,以下简称CHNS) ,由美国北卡罗来那大学和中国预防医学科学院联合执行。这是一个追踪调查,时间分别是1989 年、1991年、1993 年、1997 年、2000 年和2004 年。调查依据地理位置、经济发展程度、公共资源的丰裕程度和健康指数来进行,样本由覆盖中国东部、中部和西部8
个省份随机抽取的家庭户组成②,这些省份无论是在地理位置上还是在经济发展水平上都具有多样性,因此可以作为一个比较有代表性的样本来研究当代中国(朱农等,2008) 。除了选取每个省的省城和较低收入的城市外,在每个省依据收入分层(高、中、低) 和一定的权重随机抽取4 个县,每个县抽取县城和镇,按收入分层抽取3 个村落,每个村20 户。Shi Xinzheng 等(2002) 把1997 年8个省的样本与国家统计局的统计数据进行了对比,发现CHNS 样本中农村和城镇居民家庭的收入稍低于国家统计局的调查, 但差别不是很大。魏众( 2004 ) 、王海港(2005) ,Li 等(2006) ,Zhang 等(2006) ,朱农等(2008)等认为样本具有较好的代表性,并使用该调查的部分数据来分析中国的收入不平等。
4.3 西南财大的调查数据
西南财大开展了中国家庭金融调查(China Household Finance Survey,CHFS),抽样方案采用了分层、三阶段与规模度量成比例(PPS)的抽样设计。初级抽样单元(PSU)为全国除西藏、新疆、内蒙和港澳地区外的2585个市/县。第二阶段抽样将直接从市/县中抽取居委会/村委会;最后在居委会/村委会中抽取住户。每个阶段抽样的实施都采用了PPS抽样方法,其权重为该抽样单位的人口数(或户数)。CHFS首轮调查的户数设定为8000——8500户。从可操作性角度出发,各阶段样本数设定如下:首先,根据城乡以及地区经济发展水平,末端抽样的户数(即从每个居委会/村委会抽取的户数)设定在20-50户之间,其平均户数约为25户;其次,在每个市/县中抽取的居委会/村委会数量为4;最后可以计算得到抽取的市/县个数约为8000÷(4×25)=80。该抽样调查作于2011年,实际样本数8400多个。
1、横坐标的家庭百分比的计算是按从低收入到高收入的排序后计算的,如果没有这个假设,下面的计算没意义。
2、
没看懂?
基尼系数应该是:图中黄色部分面积与外面大三角形面积之比。